
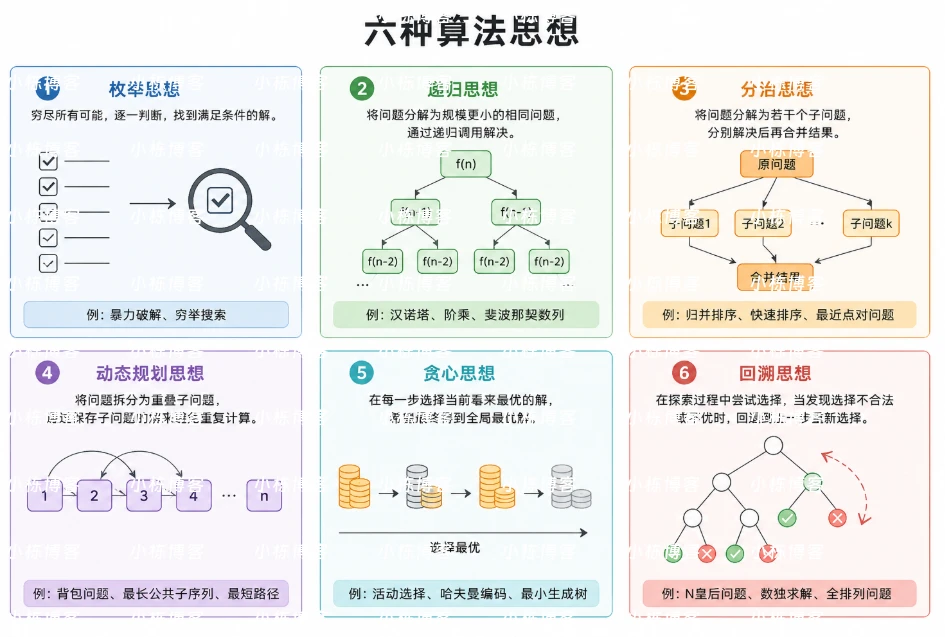
编程算法的六大思想
很多算法问题表面千奇百怪,本质上都能归到几个核心思想里。掌握这几个思想,看到新题能很快判断"用哪种解法"。本文梳理 6 种经典算法思想:递归、分治、贪心、动态规划、回溯、分支限界。每种带原理 + 优缺点 + 代码示例。
1. 递归算法
策略
递归是直接或间接调用自己的算法。本质上是把大问题拆成"同结构的小问题",通过解决小问题来解决大问题。
递归的两个要素:
- 递归基(base case) —— 最小子问题的直接解
- 递归式 —— 大问题如何用小问题表达
优缺点
优点:实现简单,易理解。某些问题(树、图遍历)天然递归。
缺点:
- 运行效率比普通循环低
- 每次递归调用占栈空间,递归太深 → 栈溢出
- 重复子问题计算(如朴素斐波那契) → 时间爆炸
示例:斐波那契数列
function getElementById(node, id){}朴素递归时间复杂度 O(2^n),很差。改用记忆化或迭代后能降到 O(n)。
2. 分治算法
策略:把问题分解成几个独立的子问题,递归解决子问题,再合并结果。"分而治之"。
跟递归的区别:递归只是"调自己",分治强调"拆分 + 合并"。所有分治都用递归实现,但不是所有递归都是分治。
典型例子:归并排序
function getElementById(node, id){
// 当前结点不存在,已经到了叶子结点了还没有找到,返回 null
if(!node) return null
// 当前结点的 id 符合查找条件,返回当前结点
if(node.id === id) return node
}时间复杂度 O(n log n),比冒泡 O(n²) 快得多。其他经典分治:快速排序、二分查找、最大子段和、矩阵快速幂。
3. 贪心算法
策略:每一步都选择当前看起来最好的选项,不回头。希望通过"局部最优"达到"全局最优"。
关键:不是所有问题都能贪心。能用贪心的问题必须满足"贪心选择性质" —— 局部最优能导致全局最优。
例子:找零钱
function getElementById(node, id){
// 当前结点不存在,已经到了叶子结点了还没有找到,返回 null
if(!node) return null
// 当前结点的 id 符合查找条件,返回当前结点
if(node.id === id) return node
// 前结点的 id 不符合查找条件,继续查找它的每一个子结点
for(var i = 0; i < node.childNodes.length; i++){
// 递归查找它的每一个子结点
var found = getElementById(node.childNodes[i], id);
if(found) return found;
}
return null;
}当面值是 [1, 5, 10, 25, 50, 100] 这种"良好"的体系时,贪心一定最优。但如果面值是 [1, 3, 4],贪心找 6 块会选 4+1+1(三个币),实际最优是 3+3(两个币)。贪心不适用。
4. 动态规划
策略:把问题拆成子问题,把子问题的解存起来(memoization),避免重复计算。"用空间换时间"。
关键三要素:
- 最优子结构:大问题的最优解可以从子问题的最优解推出
- 重叠子问题:解决大问题时,会反复用到同一些子问题
- 无后效性:子问题一旦解决,值不再变
例子:斐波那契(动态规划版)
function getElementById(node, id){
if(!node) return null;
if(node.id === id) return node;
for(var i = 0; i < node.childNodes.length; i++){
var found = getElementById(node.childNodes[i], id);
if(found) return found;
}
return null;
}
getElementById(document, "d-cal");时间从递归版的 O(2^n) 降到 O(n),空间 O(n)。
例子:0-1 背包问题
function getByElementId(node, id){
//遍历所有的Node
while(node){
if(node.id === id) return node;
node = nextElement(node);
}
return null;
}经典 DP 问题,动态规划的"hello world"。
5. 回溯算法
策略:在求解过程中,如果发现"当前路径不行",就回退一步,换条路再试。本质是深度优先搜索 + 剪枝。
典型问题特征:
- 需要枚举所有可能性
- 有"约束条件",不满足就剪枝
- 常见:排列组合、N 皇后、迷宫、数独
例子:N 皇后
// 深度遍历
function nextElement(node){
// 先判断是否有子结点
if(node.children.length) {
// 有则返回第一个子结点
return node.children[0];
}
// 再判断是否有相邻结点
if(node.nextElementSibling){
// 有则返回它的下一个相邻结点
return node.nextElementSibling;
}
// 否则,往上返回它的父结点的下一个相邻元素,相当于上面递归实现里面的for循环的i加1
while(node.parentNode){
if(node.parentNode.nextElementSibling) {
return node.parentNode.nextElementSibling;
}
node = node.parentNode;
}
return null;
}例子:数独求解
function binarySearch(items, item) {
// low、mid、high将数组分成两组
var low = 0,
high = items.length - 1,
mid = Math.floor((low+high)/2),
elem = items[mid]
// ...
}6. 分支限界算法
策略:跟回溯类似,但用 BFS(广度优先)而不是 DFS,且加上"限界函数"剪枝 —— 算出剩余部分的上界,如果已经不如当前最优,直接放弃整个分支。
跟回溯的区别:
- 回溯:DFS,找一个解就停 / 找所有解
- 分支限界:BFS,找"最优解"(最大 / 最小)
典型问题
- 0-1 背包(求最大价值)
- 旅行商问题
- 任务分配
while(low <= high) {
if(elem < item) { // 比中间数高
low = mid + 1
} else if(elem > item) { // 比中间数低
high = mid - 1
} else { // 相等
return mid
}
}选哪种思想:决策表
| 问题特征 | 推荐思想 |
|---|---|
| 大问题可分解为同结构小问题(数学归纳法) | 递归 |
| 问题能拆成独立子问题,各自求解后合并 | 分治 |
| 每步选局部最优能保证全局最优 | 贪心 |
| 有最优子结构 + 重叠子问题 | 动态规划 |
| 需要枚举所有可能性 + 有约束剪枝 | 回溯 |
| 求最值 + 可以用界限剪枝 | 分支限界 |
剩下的代码示例
function binarySearch(items, item) {
var low = 0,
high = items.length - 1,
mid, elem
while(low <= high) {
mid = Math.floor((low+high)/2)
elem = items[mid]
if(elem < item) {
low = mid + 1
} else if(elem > item) {
high = mid - 1
} else {
return mid
}
}
return -1
}function binarySearch(items, item) {
// 快排
quickSort(items)
var low = 0,
high = items.length - 1,
mid, elem
while(low <= high) {
mid = Math.floor((low+high)/2)
elem = items[mid]
if(elem < item) {
low = mid + 1
} else if(elem > item) {
high = mid - 1
} else {
return mid
}
}
return -1
}
// 测试
var arr = [2,3,1,4]
binarySearch(arr, 3)
// 2
binarySearch(arr, 5)
// -1var string = "abbc"
var regex = /ab{1,3}c/
console.log( string.match(regex) )
// \["abbc", index: 0, input: "abbc", groups: undefined\]dp[n] = dp[n−1] + dp[n−2]// 第 0 级 1 种方案
dp[0]=1
// 第 1 级也是 1 种方案
dp[1]=1let climbStairs = function(n) {
let dp = [1, 1]
for(let i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2]
}
return dp[n]
}let climbStairs = function(n) {
let res = 1, n1 = 1, n2 = 1
for(let i = 2; i <= n; i++) {
res = n1 + n2
n1 = n2
n2 = res
}
return res
}学习路径建议
- 先掌握递归 —— 写斐波那契、阶乘、树遍历,熟悉"调用栈"的感觉
- 动态规划是重头 —— 面试 / 工程问题里出现频率最高,投入最多时间。从 0-1 背包、最长子序列、编辑距离开始
- 回溯练 N 皇后 + 数独 + 全排列,理解"试错-回退"的模板
- 贪心靠经验,做多了能直觉判断"这题贪不贪"
- 分治和分支限界 —— 工程里相对少用,理解原理即可
推荐资源:LeetCode 按 tag 刷题(动态规划 tag 至少做 50 道),《算法导论》入门四章打基础,看 Tushar Roy / 花花酱的 YouTube 视频建立直觉。
 —— 别看了 · 2026
—— 别看了 · 2026